Using Lookup Tables
Note
This example focuses on how to implement non-linear storage elements in RTC-Tools using lookup tables. It assumes basic exposure to RTC-Tools. If you are a first-time user of RTC-Tools, see Filling a Reservoir.
This example also uses goal programming in the formulation. If you are unfamiliar with goal programming, please see Goal Programming: Defining Multiple Objectives.
The Model
Note
This example uses the same hydraulic model as the basic example. For a detalied explaination of the hydraulic model, see Filling a Reservoir.
In OpenModelica Connection Editor, the model looks like this:
In text mode, the Modelica model is as follows (with annotation statements removed):
1model Example
2 Deltares.ChannelFlow.SimpleRouting.BoundaryConditions.Inflow inflow;
3 Deltares.ChannelFlow.SimpleRouting.Storage.Storage storage(V(nominal=4e5, min=2e5, max=6e5));
4 Deltares.ChannelFlow.SimpleRouting.BoundaryConditions.Terminal outfall;
5 input Modelica.Units.SI.VolumeFlowRate Q_in(fixed = true);
6 input Modelica.Units.SI.VolumeFlowRate Q_release(fixed = false, min = 0.0, max = 10.0);
7equation
8 connect(inflow.QOut, storage.QIn);
9 connect(storage.QOut, outfall.QIn);
10 storage.Q_release = Q_release;
11 inflow.Q = Q_in;
12end Example;
The Optimization Problem
The python script consists of the following blocks:
Import of packages
Declaration of Goals
Declaration of the optimization problem class
Constructor
Declaration of a
pre()methodSpecification of Goals
Declaration of a
priority_completed()methodDeclaration of a
post()methodAdditional configuration of the solver
A run statement
Importing Packages
For this example, the import block is as follows:
1import numpy as np
2
3from rtctools.optimization.collocated_integrated_optimization_problem import (
4 CollocatedIntegratedOptimizationProblem,
5)
6from rtctools.optimization.csv_lookup_table_mixin import CSVLookupTableMixin
7from rtctools.optimization.csv_mixin import CSVMixin
8from rtctools.optimization.goal_programming_mixin import GoalProgrammingMixin, StateGoal
9from rtctools.optimization.modelica_mixin import ModelicaMixin
Declaring Goals
Goals are defined as classes that inherit the Goal parent class. The
components of goals can be found in Multi-objective optimization. In
this example, we use the helper goal class, StateGoal.
First, we have a high priority goal to keep the water volume within a minimum and maximum. We use a water volume goal instead of a water level goal when the volume-storage relation of the storage element is non-linear. The volume of water in the storage element behaves linearly, while the water level does not.
However, goals are usually defined in the form of water level goals. We will
convert the water level goals into volume goals within the optimization
problem class, so we define the __init__() method so we can pass the
values of the goals in later. We call the super() method to avoid
overwriting the __init__() method of the parent class.
13class WaterVolumeRangeGoal(StateGoal):
14 # We want to add a water volume range goal to our optimization. However, at
15 # the time of defining this goal we still do not know what the value of the
16 # min and max are. We add an __init__() method so that the values of these
17 # goals can be defined when the optimization problem class instantiates
18 # this goal.
19 def __init__(self, optimization_problem):
20 # Assign V_min and V_max the the target range
21 self.target_min = optimization_problem.get_timeseries("V_min")
22 self.target_max = optimization_problem.get_timeseries("V_max")
23 super().__init__(optimization_problem)
24
25 state = "storage.V"
26 priority = 1
We also want to save energy, so we define a goal to minimize Q_release. This
goal has a lower priority.
29class MinimizeQreleaseGoal(StateGoal):
30 # GoalProgrammingMixin will try to minimize the following state:
31 state = "Q_release"
32 # The lower the number returned by this function, the higher the priority.
33 priority = 2
34 # The penalty variable is taken to the order'th power.
35 order = 1
Note that this goal is phrased different from what we have seen before. In the Filling a Reservoir
example, we had as a goal to minimize the integral of Q_release; now, we have a path goal
to minimize Q_release at every time step. These two formulations come down to the
same thing (and if you replace one by the other the result stays the same).
Optimization Problem
Next, we construct the class by declaring it and inheriting the desired parent classes.
38class Example(
39 GoalProgrammingMixin,
40 CSVLookupTableMixin,
41 CSVMixin,
42 ModelicaMixin,
43 CollocatedIntegratedOptimizationProblem,
44):
The method pre() is already defined in RTC-Tools, but we would like to add
a line to it to create a variable for storing intermediate results. To do this,
we declare a new pre() method, call super().pre() to ensure
that the original method runs unmodified, and add in a variable declaration to
store our list of intermediate results.
We also want to convert our water level (H) range goal into a water volume (V) range
goal. Some values H and what value V they correspond to, for this specific storage element
are found in examples/lookup_table/input/lookup_tables/storage_V.csv.
Interpolation between these points is done by fitting a smooth curve
(so-called Cubic B-Splines, which are polynomials of degree 3) through the points.
The original table needs to have at least 4 rows for this method to work.
We can access the resulting function describing the water level-storage
relation using the lookup_table() method. We cache the functions for
convenience. The lookup_storage_V() method can convert timeseries objects,
and we save the water volume goal bounds as timeseries.
50 def pre(self):
51 super().pre()
52 # Empty list for storing intermediate_results
53 self.intermediate_results = []
54
55 # Cache lookup tables for convenience and legibility
56 _lookup_tables = self.lookup_tables(ensemble_member=0)
57 self.lookup_storage_V = _lookup_tables["storage_V"]
58
59 # Non-varrying goals can be implemented as a timeseries like this:
60 self.set_timeseries("H_min", np.ones_like(self.times()) * 0.44, output=False)
61
62 # Q_in is a varying input and is defined in timeseries_import.csv
63 # However, if we set it again here, it will be added to the output file
64 self.set_timeseries("Q_in", self.get_timeseries("Q_in"))
65
66 # Convert our water level constraints into volume constraints
67 self.set_timeseries("V_max", self.lookup_storage_V(self.get_timeseries("H_max")))
68 self.set_timeseries("V_min", self.lookup_storage_V(self.get_timeseries("H_min")))
Notice that H_max was not defined in pre(). This is because it was defined as a timeseries import. We access timeseries using get_timeseries() and store them using set_timeseries(). Once a timeseries is set, we can access it later. In addition, all timeseries that are set are automatically included in the output file. You can find more information on timeseries here Basics.
Now we pass in the goals. We want to apply our goals to every timestep, so we
use the path_goals() method. This is a method that returns a list of the
goals we defined above. The WaterVolumeRangeGoal needs to be instantiated
with the new water volume timeseries we just defined.
70 def path_goals(self):
71 g = []
72 g.append(WaterVolumeRangeGoal(self))
73 g.append(MinimizeQreleaseGoal(self))
74 return g
If all we cared about were the results, we could end our class declaration here. However, it is usually helpful to track how the solution changes after optimizing each priority level. To track these changes, we need to add three methods.
We define the priority_completed() method to inspect and summerize the
results. These are appended to our intermediate results variable after each
priority is completed.
79 def priority_completed(self, priority):
80 results = self.extract_results()
81 self.set_timeseries("storage_V", results["storage.V"])
82
83 _max = self.get_timeseries("V_max").values
84 _min = self.get_timeseries("V_min").values
85 storage_V = self.get_timeseries("storage_V").values
86
87 # A little bit of tolerance when checking for acceptance.
88 tol = 10
89 _max += tol
90 _min -= tol
91 n_level_satisfied = sum(np.logical_and(_min <= storage_V, storage_V <= _max))
92 q_release_integral = sum(results["Q_release"])
93 self.intermediate_results.append((priority, n_level_satisfied, q_release_integral))
We output our intermediate results using the post() method. Again, we nedd
to call the super() method to avoid overwiting the internal method.
95 def post(self):
96 # Call super() class to not overwrite default behaviour
97 super().post()
98 for priority, n_level_satisfied, q_release_integral in self.intermediate_results:
99 print(f"\nAfter finishing goals of priority {priority}:")
100 print(f"Volume goal satisfied at {n_level_satisfied} of {len(self.times())} time steps")
101 print(f"Integral of Q_release = {q_release_integral:.2f}")
Finally, we want to apply some additional configuration, reducing the amount of information the solver outputs:
104 def solver_options(self):
105 options = super().solver_options()
106 solver = options["solver"]
107 options[solver]["print_level"] = 1
108 return options
Run the Optimization Problem
To make our script run, at the bottom of our file we just have to call
the run_optimization_problem() method we imported on the optimization
problem class we just created.
112run_optimization_problem(Example)
The Whole Script
All together, the whole example script is as follows:
1import numpy as np
2
3from rtctools.optimization.collocated_integrated_optimization_problem import (
4 CollocatedIntegratedOptimizationProblem,
5)
6from rtctools.optimization.csv_lookup_table_mixin import CSVLookupTableMixin
7from rtctools.optimization.csv_mixin import CSVMixin
8from rtctools.optimization.goal_programming_mixin import GoalProgrammingMixin, StateGoal
9from rtctools.optimization.modelica_mixin import ModelicaMixin
10from rtctools.util import run_optimization_problem
11
12
13class WaterVolumeRangeGoal(StateGoal):
14 # We want to add a water volume range goal to our optimization. However, at
15 # the time of defining this goal we still do not know what the value of the
16 # min and max are. We add an __init__() method so that the values of these
17 # goals can be defined when the optimization problem class instantiates
18 # this goal.
19 def __init__(self, optimization_problem):
20 # Assign V_min and V_max the the target range
21 self.target_min = optimization_problem.get_timeseries("V_min")
22 self.target_max = optimization_problem.get_timeseries("V_max")
23 super().__init__(optimization_problem)
24
25 state = "storage.V"
26 priority = 1
27
28
29class MinimizeQreleaseGoal(StateGoal):
30 # GoalProgrammingMixin will try to minimize the following state:
31 state = "Q_release"
32 # The lower the number returned by this function, the higher the priority.
33 priority = 2
34 # The penalty variable is taken to the order'th power.
35 order = 1
36
37
38class Example(
39 GoalProgrammingMixin,
40 CSVLookupTableMixin,
41 CSVMixin,
42 ModelicaMixin,
43 CollocatedIntegratedOptimizationProblem,
44):
45 """
46 An extention of the goal programming example that shows how to incorporate
47 non-linear storage elements in the model.
48 """
49
50 def pre(self):
51 super().pre()
52 # Empty list for storing intermediate_results
53 self.intermediate_results = []
54
55 # Cache lookup tables for convenience and legibility
56 _lookup_tables = self.lookup_tables(ensemble_member=0)
57 self.lookup_storage_V = _lookup_tables["storage_V"]
58
59 # Non-varrying goals can be implemented as a timeseries like this:
60 self.set_timeseries("H_min", np.ones_like(self.times()) * 0.44, output=False)
61
62 # Q_in is a varying input and is defined in timeseries_import.csv
63 # However, if we set it again here, it will be added to the output file
64 self.set_timeseries("Q_in", self.get_timeseries("Q_in"))
65
66 # Convert our water level constraints into volume constraints
67 self.set_timeseries("V_max", self.lookup_storage_V(self.get_timeseries("H_max")))
68 self.set_timeseries("V_min", self.lookup_storage_V(self.get_timeseries("H_min")))
69
70 def path_goals(self):
71 g = []
72 g.append(WaterVolumeRangeGoal(self))
73 g.append(MinimizeQreleaseGoal(self))
74 return g
75
76 # We want to print some information about our goal programming problem. We
77 # store the useful numbers temporarily, and print information at the end of
78 # our run (see post() method below).
79 def priority_completed(self, priority):
80 results = self.extract_results()
81 self.set_timeseries("storage_V", results["storage.V"])
82
83 _max = self.get_timeseries("V_max").values
84 _min = self.get_timeseries("V_min").values
85 storage_V = self.get_timeseries("storage_V").values
86
87 # A little bit of tolerance when checking for acceptance.
88 tol = 10
89 _max += tol
90 _min -= tol
91 n_level_satisfied = sum(np.logical_and(_min <= storage_V, storage_V <= _max))
92 q_release_integral = sum(results["Q_release"])
93 self.intermediate_results.append((priority, n_level_satisfied, q_release_integral))
94
95 def post(self):
96 # Call super() class to not overwrite default behaviour
97 super().post()
98 for priority, n_level_satisfied, q_release_integral in self.intermediate_results:
99 print(f"\nAfter finishing goals of priority {priority}:")
100 print(f"Volume goal satisfied at {n_level_satisfied} of {len(self.times())} time steps")
101 print(f"Integral of Q_release = {q_release_integral:.2f}")
102
103 # Any solver options can be set here
104 def solver_options(self):
105 options = super().solver_options()
106 solver = options["solver"]
107 options[solver]["print_level"] = 1
108 return options
109
110
111# Run
112run_optimization_problem(Example)
Running the Optimization Problem
Following the execution of the optimization problem, the post() method
should print out the following lines:
After finishing goals of priority 1:
Volume goal satisfied at 12 of 12 time steps
Integral of Q_release = 42.69
After finishing goals of priority 2:
Volume goal satisfied at 12 of 12 time steps
Integral of Q_release = 42.58
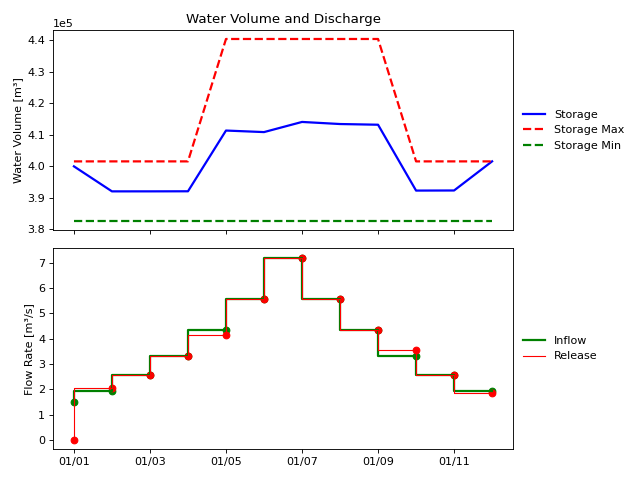
As the output indicates, while optimizing for the priority 1 goal, no attempt
was made to minimize the integral of Q_release. The only objective was to
minimize the number of states in violation of the water level goal.
After optimizing for the priority 2 goal, the solver was able to find a solution
that reduced the integral of Q_release without increasing the number of
timesteps where the water level exceded the limit.
Extracting Results
The results from the run are found in output/timeseries_export.csv. Any
CSV-reading software can import it, but this is how results can be plotted using
the python library matplotlib:
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import numpy as np
# Import Data
data_path = "../../../examples/lookup_table/reference_output/timeseries_export.csv"
results = np.genfromtxt(
data_path, delimiter=",", encoding=None, dtype=None, names=True, case_sensitive="lower"
)
# Get times as datetime objects
times = [datetime.strptime(x, "%Y-%m-%d %H:%M:%S") for x in results["time"]]
# Generate Plot
n_subplots = 2
fig, axarr = plt.subplots(n_subplots, sharex=True, figsize=(8, 3 * n_subplots))
axarr[0].set_title("Water Volume and Discharge")
# Upper subplot
axarr[0].set_ylabel("Water Volume [m³]")
axarr[0].ticklabel_format(style="sci", axis="y", scilimits=(0, 0))
axarr[0].plot(times, results["storage_v"], label="Storage", linewidth=2, color="b")
axarr[0].plot(times, results["v_max"], label="Storage Max", linewidth=2, color="r", linestyle="--")
axarr[0].plot(times, results["v_min"], label="Storage Min", linewidth=2, color="g", linestyle="--")
# Lower Subplot
axarr[1].set_ylabel("Flow Rate [m³/s]")
axarr[1].scatter(times, results["q_in"], linewidth=1, color="g")
axarr[1].scatter(times, results["q_release"], linewidth=1, color="r")
# add horizontal lines to the left of these dots, to indicate that the value is attained over an
# entire timestep:
axarr[1].step(times, results["q_in"], linewidth=2, where="pre", label="Inflow", color="g")
axarr[1].step(times, results["q_release"], linewidth=1, where="pre", label="Release", color="r")
# Format bottom axis label
axarr[-1].xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
# Shrink margins
fig.tight_layout()
# Shrink each axis and put a legend to the right of the axis
for i in range(n_subplots):
box = axarr[i].get_position()
axarr[i].set_position([box.x0, box.y0, box.width * 0.8, box.height])
axarr[i].legend(loc="center left", bbox_to_anchor=(1, 0.5), frameon=False)
plt.autoscale(enable=True, axis="x", tight=True)
# Output Plot
plt.show()
(Source code, svg, png)
{kind=link}
{kind=link}
