Using an Ensemble Forecast
Note
This example is an extension of Using Lookup Tables. It assumes prior knowledge of goal programming and the lookup tables components of RTC-Tools. If you are a first-time user of RTC-Tools, see Filling a Reservoir.
Then biggest change to RTC-Tools when using an ensemble is the structure of the
directory. The folder <examples directory>\ensemble
contains a complete RTC-Tools ensemble optimization problem. An RTC-Tools
ensemble directory has the following structure:
model: This folder contains the Modelica model. The Modelica model contains the physics of the RTC-Tools model.src: This folder contains a Python file. This file contains the configuration of the model and is used to run the model.input: This folder contains the model input data pertaining to each ensemble member:ensemble.csv: a file where the names and probabilities of the ensemble members are definedforecast1the file
timeseries_import.csvthe file
initial_state.csv
forecast2timeseries_import.csvinitial_state.csv
…
output: The folder where the output is saved:forecast1timeseries_export.csv
forecast2timeseries_export.csv
…
The Model
Note
This example uses the same hydraulic model as the basic example. For a detailed explanation of the hydraulic model, see Filling a Reservoir.
In OpenModelica Connection Editor, the model looks like this:
In text mode, the Modelica model is as follows (with annotation statements removed):
1model Example
2 Deltares.ChannelFlow.SimpleRouting.BoundaryConditions.Inflow inflow;
3 Deltares.ChannelFlow.SimpleRouting.Storage.Storage storage(V(nominal=4e5, min=2e5, max=6e5));
4 Deltares.ChannelFlow.SimpleRouting.BoundaryConditions.Terminal outfall;
5 input Modelica.Units.SI.VolumeFlowRate Q_in(fixed = true);
6 input Modelica.Units.SI.VolumeFlowRate Q_release(fixed = false, min = 0.0, max = 6.0);
7equation
8 connect(inflow.QOut, storage.QIn);
9 connect(storage.QOut, outfall.QIn);
10 storage.Q_release = Q_release;
11 inflow.Q = Q_in;
12end Example;
The Optimization Problem
The python script consists of the following blocks:
Import of packages
Declaration of Goals
Declaration of the optimization problem class
Constructor
Set
csv_ensemble_mode = TrueDeclaration of a
pre()methodSpecification of Goals
Declaration of a
priority_completed()methodDeclaration of a
post()methodAdditional configuration of the solver
A run statement
Importing Packages
For this example, the import block is as follows:
1import numpy as np
2
3from rtctools.optimization.collocated_integrated_optimization_problem import (
4 CollocatedIntegratedOptimizationProblem,
5)
6from rtctools.optimization.control_tree_mixin import ControlTreeMixin
7from rtctools.optimization.csv_lookup_table_mixin import CSVLookupTableMixin
8from rtctools.optimization.csv_mixin import CSVMixin
9from rtctools.optimization.goal_programming_mixin import GoalProgrammingMixin, StateGoal
10from rtctools.optimization.modelica_mixin import ModelicaMixin
Declaring Goals
First, we have a high priority goal to keep the water volume within a minimum and maximum.
14class WaterVolumeRangeGoal(StateGoal):
15 def __init__(self, optimization_problem):
16 # Assign V_min and V_max the the target range
17 self.target_min = optimization_problem.get_timeseries("V_min")
18 self.target_max = optimization_problem.get_timeseries("V_max")
19 super().__init__(optimization_problem)
20
21 state = "storage.V"
22 priority = 1
We also want to save energy, so we define a goal to minimize Q_release. This
goal has a lower priority.
25class MinimizeQreleaseGoal(StateGoal):
26 # GoalProgrammingMixin will try to minimize the following state
27 state = "Q_release"
28 # The lower the number returned by this function, the higher the priority.
29 priority = 2
30 # The penalty variable is taken to the order'th power.
31 order = 1
Optimization Problem
Next, we construct the class by declaring it and inheriting the desired parent classes.
34class Example(
35 GoalProgrammingMixin,
36 CSVMixin,
37 CSVLookupTableMixin,
38 ModelicaMixin,
39 ControlTreeMixin,
40 CollocatedIntegratedOptimizationProblem,
41):
We turn on ensemble mode by setting csv_ensemble_mode = True:
49
50 def pre(self):
The method pre() is already defined in RTC-Tools, but we would like to add
a line to it to create a variable for storing intermediate results. To do
this, we declare a new pre() method, call super().pre()
to ensure that the original method runs unmodified, and add in a variable
declaration to store our list of intermediate results. This variable is a
dict, reflecting the need to store results from multiple ensemble.
Because the timeseries we set will be the same for both ensemble members, we also make sure that the timeseries we set are set for both ensemble members using for loops.
50 def pre(self):
51 # Do the standard preprocessing
52 super().pre()
53
54 # Create a dict of empty lists for storing intermediate results from
55 # each ensemble
56 self.intermediate_results = {
57 ensemble_member: [] for ensemble_member in range(self.ensemble_size)
58 }
59
60 # Cache lookup tables for convenience and code legibility
61 _lookup_tables = self.lookup_tables(ensemble_member=0)
62 self.lookup_storage_V = _lookup_tables["storage_V"]
63
64 # Non-varying goals can be implemented as a timeseries
65 for e_m in range(self.ensemble_size):
66 self.set_timeseries("H_min", np.ones_like(self.times()) * 0.44, ensemble_member=e_m)
67 self.set_timeseries("H_max", np.ones_like(self.times()) * 0.46, ensemble_member=e_m)
68
69 # Q_in is a varying input and is defined in each timeseries_import.csv
70 # However, if we set it again here, it will be added to the output files
71 self.set_timeseries(
72 "Q_in", self.get_timeseries("Q_in", ensemble_member=e_m), ensemble_member=e_m
73 )
74
75 # Convert our water level goals into volume goals
76 self.set_timeseries(
77 "V_max", self.lookup_storage_V(self.get_timeseries("H_max")), ensemble_member=e_m
78 )
79 self.set_timeseries(
80 "V_min", self.lookup_storage_V(self.get_timeseries("H_min")), ensemble_member=e_m
81 )
Now we pass in the goals:
83 def path_goals(self):
84 g = []
85 g.append(WaterVolumeRangeGoal(self))
86 g.append(MinimizeQreleaseGoal(self))
87 return g
In order to better demonstrate the way that ensembles are handled in RTC-
Tools, we modify the control_tree_options() method. The default setting
allows the control tree to split at every time, but we override this method
and force it to split at a single timestep. See Extracting Results at
the bottom of the page for more information.
89 def control_tree_options(self):
90 # We want to modify the control tree options, so we override the default
91 # control_tree_options method. We call super() to get the default options
92 options = super().control_tree_options()
93 # Change the branching_times list to only contain the fifth timestep
94 options["branching_times"] = [self.times()[5]]
95 return options
We define the priority_completed() method. We ensure that it stores the
results from both ensemble members.
97 def priority_completed(self, priority):
98 # We want to print some information about our goal programming problem.
99 # We store the useful numbers temporarily, and print information at the
100 # end of our run.
101 for e_m in range(self.ensemble_size):
102 results = self.extract_results(e_m)
103 self.set_timeseries("V_storage", results["storage.V"], ensemble_member=e_m)
104
105 _max = self.get_timeseries("V_max", ensemble_member=e_m).values
106 _min = self.get_timeseries("V_min", ensemble_member=e_m).values
107 V_storage = self.get_timeseries("V_storage", ensemble_member=e_m).values
108
109 # A little bit of tolerance when checking for acceptance. This
110 # tolerance must be set greater than the tolerance of the solver.
111 tol = 10
112 _max += tol
113 _min -= tol
114 n_level_satisfied = sum(np.logical_and(_min <= V_storage, V_storage <= _max))
115 q_release_integral = sum(results["Q_release"])
116 self.intermediate_results[e_m].append((priority, n_level_satisfied, q_release_integral))
We output our intermediate results using the post() method:
118 def post(self):
119 super().post()
120 for e_m in range(self.ensemble_size):
121 print(f"\n\nResults for Ensemble Member {e_m}:")
122 for priority, n_level_satisfied, q_release_integral in self.intermediate_results[e_m]:
123 print(f"\nAfter finishing goals of priority {priority}:")
124 print(
125 f"Level goal satisfied at {n_level_satisfied} of {len(self.times())} time steps"
126 )
127 print(f"Integral of Q_release = {q_release_integral:.2f}")
Finally, we want to apply some additional configuration, reducing the amount of information the solver outputs:
130 def solver_options(self):
131 options = super().solver_options()
132 # When mumps_scaling is not zero, errors occur. RTC-Tools does its own
133 # scaling, so mumps scaling is not critical. Proprietary HSL solvers
134 # do not exhibit this error.
135 solver = options["solver"]
136 options[solver]["mumps_scaling"] = 0
137 options[solver]["print_level"] = 1
138 return options
Run the Optimization Problem
To make our script run, at the bottom of our file we just have to call
the run_optimization_problem() method we imported on the optimization
problem class we just created.
142run_optimization_problem(Example)
The Whole Script
All together, the whole example script is as follows:
1import numpy as np
2
3from rtctools.optimization.collocated_integrated_optimization_problem import (
4 CollocatedIntegratedOptimizationProblem,
5)
6from rtctools.optimization.control_tree_mixin import ControlTreeMixin
7from rtctools.optimization.csv_lookup_table_mixin import CSVLookupTableMixin
8from rtctools.optimization.csv_mixin import CSVMixin
9from rtctools.optimization.goal_programming_mixin import GoalProgrammingMixin, StateGoal
10from rtctools.optimization.modelica_mixin import ModelicaMixin
11from rtctools.util import run_optimization_problem
12
13
14class WaterVolumeRangeGoal(StateGoal):
15 def __init__(self, optimization_problem):
16 # Assign V_min and V_max the the target range
17 self.target_min = optimization_problem.get_timeseries("V_min")
18 self.target_max = optimization_problem.get_timeseries("V_max")
19 super().__init__(optimization_problem)
20
21 state = "storage.V"
22 priority = 1
23
24
25class MinimizeQreleaseGoal(StateGoal):
26 # GoalProgrammingMixin will try to minimize the following state
27 state = "Q_release"
28 # The lower the number returned by this function, the higher the priority.
29 priority = 2
30 # The penalty variable is taken to the order'th power.
31 order = 1
32
33
34class Example(
35 GoalProgrammingMixin,
36 CSVMixin,
37 CSVLookupTableMixin,
38 ModelicaMixin,
39 ControlTreeMixin,
40 CollocatedIntegratedOptimizationProblem,
41):
42 """
43 An extention of the goal programming and lookuptable examples that
44 demonstrates how to work with ensembles.
45 """
46
47 # Overide default csv_ensemble_mode = False from CSVMixin before calling pre()
48 csv_ensemble_mode = True
49
50 def pre(self):
51 # Do the standard preprocessing
52 super().pre()
53
54 # Create a dict of empty lists for storing intermediate results from
55 # each ensemble
56 self.intermediate_results = {
57 ensemble_member: [] for ensemble_member in range(self.ensemble_size)
58 }
59
60 # Cache lookup tables for convenience and code legibility
61 _lookup_tables = self.lookup_tables(ensemble_member=0)
62 self.lookup_storage_V = _lookup_tables["storage_V"]
63
64 # Non-varying goals can be implemented as a timeseries
65 for e_m in range(self.ensemble_size):
66 self.set_timeseries("H_min", np.ones_like(self.times()) * 0.44, ensemble_member=e_m)
67 self.set_timeseries("H_max", np.ones_like(self.times()) * 0.46, ensemble_member=e_m)
68
69 # Q_in is a varying input and is defined in each timeseries_import.csv
70 # However, if we set it again here, it will be added to the output files
71 self.set_timeseries(
72 "Q_in", self.get_timeseries("Q_in", ensemble_member=e_m), ensemble_member=e_m
73 )
74
75 # Convert our water level goals into volume goals
76 self.set_timeseries(
77 "V_max", self.lookup_storage_V(self.get_timeseries("H_max")), ensemble_member=e_m
78 )
79 self.set_timeseries(
80 "V_min", self.lookup_storage_V(self.get_timeseries("H_min")), ensemble_member=e_m
81 )
82
83 def path_goals(self):
84 g = []
85 g.append(WaterVolumeRangeGoal(self))
86 g.append(MinimizeQreleaseGoal(self))
87 return g
88
89 def control_tree_options(self):
90 # We want to modify the control tree options, so we override the default
91 # control_tree_options method. We call super() to get the default options
92 options = super().control_tree_options()
93 # Change the branching_times list to only contain the fifth timestep
94 options["branching_times"] = [self.times()[5]]
95 return options
96
97 def priority_completed(self, priority):
98 # We want to print some information about our goal programming problem.
99 # We store the useful numbers temporarily, and print information at the
100 # end of our run.
101 for e_m in range(self.ensemble_size):
102 results = self.extract_results(e_m)
103 self.set_timeseries("V_storage", results["storage.V"], ensemble_member=e_m)
104
105 _max = self.get_timeseries("V_max", ensemble_member=e_m).values
106 _min = self.get_timeseries("V_min", ensemble_member=e_m).values
107 V_storage = self.get_timeseries("V_storage", ensemble_member=e_m).values
108
109 # A little bit of tolerance when checking for acceptance. This
110 # tolerance must be set greater than the tolerance of the solver.
111 tol = 10
112 _max += tol
113 _min -= tol
114 n_level_satisfied = sum(np.logical_and(_min <= V_storage, V_storage <= _max))
115 q_release_integral = sum(results["Q_release"])
116 self.intermediate_results[e_m].append((priority, n_level_satisfied, q_release_integral))
117
118 def post(self):
119 super().post()
120 for e_m in range(self.ensemble_size):
121 print(f"\n\nResults for Ensemble Member {e_m}:")
122 for priority, n_level_satisfied, q_release_integral in self.intermediate_results[e_m]:
123 print(f"\nAfter finishing goals of priority {priority}:")
124 print(
125 f"Level goal satisfied at {n_level_satisfied} of {len(self.times())} time steps"
126 )
127 print(f"Integral of Q_release = {q_release_integral:.2f}")
128
129 # Any solver options can be set here
130 def solver_options(self):
131 options = super().solver_options()
132 # When mumps_scaling is not zero, errors occur. RTC-Tools does its own
133 # scaling, so mumps scaling is not critical. Proprietary HSL solvers
134 # do not exhibit this error.
135 solver = options["solver"]
136 options[solver]["mumps_scaling"] = 0
137 options[solver]["print_level"] = 1
138 return options
139
140
141# Run
142run_optimization_problem(Example)
Running the Optimization Problem
Following the execution of the optimization problem, the post() method
should print out the following lines:
Results for Ensemble Member 0:
After finishing goals of priority 1:
Level goal satisfied at 10 of 12 time steps
Integral of Q_release = 17.34
After finishing goals of priority 2:
Level goal satisfied at 9 of 12 time steps
Integral of Q_release = 17.12
Results for Ensemble Member 1:
After finishing goals of priority 1:
Level goal satisfied at 10 of 12 time steps
Integral of Q_release = 20.82
After finishing goals of priority 2:
Level goal satisfied at 9 of 12 time steps
Integral of Q_release = 20.60
This is the same output as the output for Mixed Integer Optimization: Pumps and Orifices, except now the output for each ensemble is printed.
Extracting Results
The results from the run are found in output/forecast1/timeseries_export.csv
and output/forecast2/timeseries_export.csv. Any CSV-reading software can
import it, but this is how results can be plotted using the python library
matplotlib:
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import numpy as np
from pylab import get_cmap
forecast_names = ["forecast1", "forecast2"]
dir_template = "../../../examples/ensemble/reference_output/{}/timeseries_export.csv"
# Import Data
forcasts = {}
for forecast in forecast_names:
data_path = dir_template.format(forecast)
forcasts[forecast] = np.genfromtxt(
data_path, delimiter=",", encoding=None, dtype=None, names=True, case_sensitive="lower"
)
# Get times as datetime objects
times = [datetime.strptime(x, "%Y-%m-%d %H:%M:%S") for x in forcasts[forecast_names[0]]["time"]]
n_subplots = 3
fig, axarr = plt.subplots(n_subplots, sharex=True, figsize=(8, 4 * n_subplots))
axarr[0].set_title("Water Volume and Discharge")
cmaps = ["Blues", "Greens"]
shades = [0.5, 0.8]
# Upper Subplot
axarr[0].set_ylabel("Water Volume in Storage [m³]")
axarr[0].ticklabel_format(style="sci", axis="y", scilimits=(0, 0))
# Lower Subplots
axarr[1].set_ylabel("Flow Rate [m³/s]")
axarr[2].set_ylabel("Flow Rate [m³/s]")
# Plot Ensemble Members
for idx, forecast in enumerate(forecast_names):
# Upper Subplot
results = forcasts[forecast]
if idx == 0:
axarr[0].plot(times, results["v_max"], label="Max", linewidth=2, color="r", linestyle="--")
axarr[0].plot(times, results["v_min"], label="Min", linewidth=2, color="g", linestyle="--")
axarr[0].plot(
times,
results["v_storage"],
label=forecast + ":Volume",
linewidth=2,
color=get_cmap(cmaps[idx])(shades[1]),
)
# middle subplot
# put dots to see at which times the decision variables are defined:
axarr[1].scatter(times, results["q_in"], linewidth=1, color=get_cmap(cmaps[idx])(shades[0]))
axarr[1].scatter(
times, results["q_release"], linewidth=1, color=get_cmap(cmaps[idx])(shades[1])
)
# add horizontal lines to the left of these dots, to indicate that the value is attained over
# an entire timestep:
axarr[1].step(
times,
results["q_in"],
linewidth=2,
where="pre",
label=f"{forecast}:Inflow",
color=get_cmap(cmaps[idx])(shades[0]),
)
axarr[1].step(
times,
results["q_release"],
linewidth=1,
where="pre",
label=f"{forecast}:Release",
color=get_cmap(cmaps[idx])(shades[1]),
)
# Lower Subplot
axarr[2].plot(
times,
results["q_in"],
label=f"{forecast}:Inflow",
linewidth=2,
color=get_cmap(cmaps[idx])(shades[0]),
)
axarr[2].plot(
times,
results["q_release"],
label=f"{forecast}:Release",
linewidth=2,
color=get_cmap(cmaps[idx])(shades[1]),
)
# Format bottom axis labels
axarr[-1].xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
# Shrink margins
fig.tight_layout()
# Shrink each axis and put a legend to the right of the axis
for i in range(len(axarr)):
box = axarr[i].get_position()
axarr[i].set_position([box.x0, box.y0, box.width * 0.75, box.height])
axarr[i].legend(loc="center left", bbox_to_anchor=(1, 0.5), frameon=False)
plt.autoscale(enable=True, axis="x", tight=True)
# Output Plot
plt.show()
(Source code, svg, png)
{kind=link}
{kind=link}

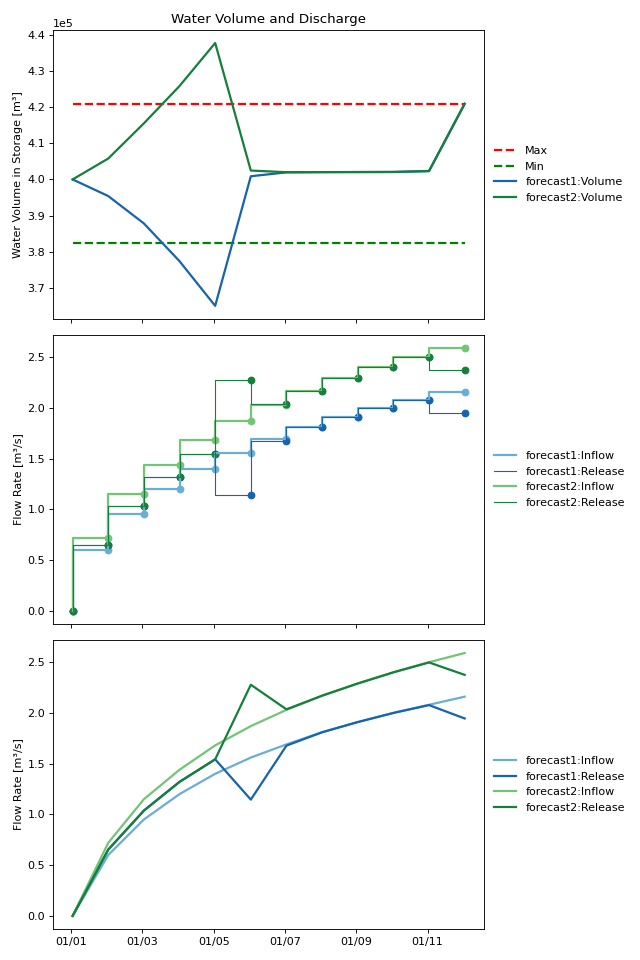
This plots the inflow and release values in two different ways: the middle graph depicts them in the same way you have seen until now (and this is how they truly should be interpreted). The lower plot shows the same points, but connected with line segments. This makes it easier to see where the flows diverge.
Observations
Note that in the results plotted above, the control tree follows a single path and does not branch until it arrives at the first branching time. Up until the branching point, RTC-Tools is making decisions that enhance the flexibility of the system so that it can respond as ideally as possible to whichever future emerges. In the case of two forecasts, this means taking a path that falls between the two possible futures. This will cause the water level to diverge from the ideal levels as time progresses. While this appears to be suboptimal, it is preferable to simply gambling on one of the forecasts coming true and ignoring the other. Once the branching time is reached, RTC-Tools is allowed to optimize for each individual branch separately. Immediately, RTC-Tools applies the corrective control needed to get the water levels into the acceptable range. If the operator simply picks a forecast to use and guesses wrong, the corrective control will have to be much more drastic and potentially catastrophic.